1. 从最优化引出的拉格朗日乘数法
1.1 一个最简单的无约束优化问题
在学习与工程之中,我们时常会遇到一些优化的问题,也就是要对某个目标函数求取极值,最简单的形式如下。
\[ \large \min_{x \in \mathbb{R^n}}{f(x)} \]
这个式子表达的含义是以 \(x\) 为自变量,求取 \(f(x)\) 的最小值。如果想要求取最大值,可以把 \(f\) 加一个符号,这样把 \(\max_{x}{f(x)}\) 转换为等价的 \(\min_{x}{-f(x)}\) 就行了。另外需要注意的是 \(x\) 并非一个标量数值,而是n维实数空间上的一个向量。
这样的例子有很多,最常见的就比如我们在机器学习中经常碰到的最小化代价函数。对于这样的问题,我们求解的方法很简单,只要能够求出一个点 \(x^\prime\),使得 \(\nabla f(x^\prime) = 0\) 即可。
当然我们也知道,只有当 \(f\) 是凸函数的时候,这样求出来的才是全局最优点,否则不过是个局部最优点罢了。不过这就不在我们的讨论范围内了。现在我们姑且假定讨论的 \(f\) 都是凸函数。
1.2 带有等式约束的优化问题
我们在上一节的基础上进一步,如果 \(f\) 是有约束的呢?
\[ \large \begin{aligned} &\min_{x \in \mathbb{R^n}}{f(x)}\\ &s.t \quad h_i(x) = 0, i \in [1, l] \end{aligned} \]
在这个问题中,我们对在定义域上的 \(x\) 有了 \(l\) 个等式约束 \(h_i\)。这样一来我们就不能随意的计算导数等于0的点作为最优点了。那要怎么做呢?
这时就需要用到拉格朗日乘数法了,具体而言,我们首先来构建这么一个拉格朗日函数:
\[ \begin{aligned} &L(x, \lambda) = f(x) + \sum_{i=1}^{l}\lambda_ih_i(x)\\ &x \in \mathbb{R^n}, \lambda \in \mathbb{R^l} \end{aligned} \] 这里 \(\lambda\) 是新引入的参数,被称为拉格朗日乘子,在这里它是一个 \(l\) 维的向量。
接着我们需要求解方程:
\[ \left\{ \begin{aligned} &\frac{\partial L}{\partial x} = 0\\ &h_i(x) = 0 \end{aligned} \right. \]
求解出来的结果 \(x^\prime\) 必然就是最大值或最小值对应的点,只要稍加检验就可以得出结果了。
那么为什么会这样呢?这里我们稍加解释,如下图所示,\(f(x, y)\) 是我们的目标函数 \(f(x)\),而 \(g(x, y)\) 则是我们的约束条件 \(h(x)\)。
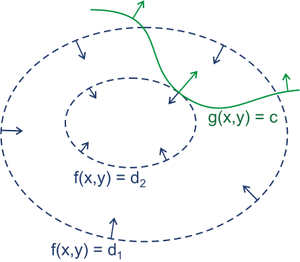
显然我们的目标就是求出在 \(f\) 和 \(g\) 的交点上的最小值。稍加思索,我们不难发现,这样的点一定是两个 \(g\) 和 \(f\) 的某个等高线相切的一个点。原因很简单:假定我们的目标 \(x^*\) 不是切点,那么它必然可以沿着负梯度的方向朝着更低的方向前进,那这就意味着它必然不是最小值对应的点。
所以我们就有结论:
若 \(x^*\) 是被等式 \(h\) 约束的最优化问题 \(\min f\) 的解,则 \(f\) 和 \(h\) 在 \(x^*\) 处相切
既然 \(f\) 和 \(h\) 在 \(x^*\) 上相切,那就意味着二者在这一点的梯度的方向相同,即: \[ \nabla f = \lambda \nabla h,\quad \lambda \not = 0 \]
稍加整理,我们就可以得出结论,只要 \(x\) 满足: \[ \left\{ \begin{aligned} &\frac{\mathbb{d}f}{\mathbb{d}x} + \lambda\frac{\mathbb{d}h}{\mathbb{d}x} = 0\\ &h(x) = 0 \end{aligned} \right. \] 那么 \(x\) 就是我们希望的最优点。稍加整理就是上面的拉格朗日函数的形式了。
更详细的解释见这里。
1.3 再加上不等式约束
然而实际生活中我们可能碰到的问题比上面的还要复杂,不仅仅是有等式约束,还可能会有不等式约束。
现在假定 \(f(x),\ c_i(x),\ h_i(x)\) 都是定义在 \(\mathbb{R^n}\) 上的连续可微函数,则考虑约束最优化问题: \[ \large \begin{aligned} &\min_{x \in \mathbb{R^n}}{f(x)}\\ &s.t \quad c_i(x) \leqslant 0, i \in [1, k]\\ &\qquad h_j(x) = 0, j \in [1, l]\\ \end{aligned} \tag{1} \]
式(1)就是我们实际会遇到的优化问题的基本形式。如何求解这个优化问题也就是这篇文章主要要探讨的。
关于具体如何求解,我们从第三节再开始讲其。第二节中,我们主要先把一些需要用到的数学概念理清了。
2. 预备的数学知识
2.1 数学符号说明
\(\min\)/\(\max\) 符号
在接下来你会看到一大堆这样: \[ \min_{x} f(x) \tag{a} \] 这样的: \[ \max_{x \in D}f(x, \lambda) \tag{b} \] 甚至这样的: \[ \max_{\lambda}\min_{x}f(x, \lambda) \tag{c} \] 所以如果不把 \(\min_x\) 或者 \(\max_x\) 这个符号搞清楚的话,接下来可能会很难受。
简而言之,式子(a)的意思是对于函数 \(f(x)\) ,考察 \(x\) (可以理解为改变 \(x\)),来找到它的最小值。有时候在 \(\min\) 的下标的位置还会带上一些限制条件,比如(b)中的 \(x \in D\),意思就是“考察在集合 D 中的 \(x\)”。
这个符号的含义在函数只有一个自变量 \(x\) 的时候倒不会出现什么混淆,但是当自变量不止一个的时候就容易弄混了。来我们来看看式子(b): \[ \max_{x \in D}f(x, \lambda) \tag{b} \] 函数 \(f\) 是一个关于 \(x, \lambda\) 两个变量的函数。所以式子(b)的含义就是固定 \(\lambda\) 不变,改变 \(x\) 从而使得 \(f\) 的值最小。有时候可能会看到这样的格式: \[ g(\lambda) = \max_{x \in D}f(x, \lambda) \] 这个式子的意思是: - \(g(\lambda)\) 是一个关于 \(\lambda\) 的函数 - 当 \(\lambda = y\) 时,\(g(\lambda)\) 的取值为:固定 \(f(x, \lambda)\) 中的 \(\lambda = y\),变动 \(x\) 时 \(f\) 能取到的最大值
比如: \[ \begin{aligned} &&f(x, y) &= x^2 + y^2\\ &&g(y) &= \min_{x \in D}f(x, y)\\ &&g(4) &= \min_{x \in D}f(x, 4)\\ && &= \min_{x \in D}(x^2 + 16)\\ && &= 0 + 16 = 16 \end{aligned} \]
在进一步,有时候 \(\min\) 还有 \(\max\) 会像(c)一样叠加在一起: \[ v = \max_{\lambda}\min_{x}f(x, \lambda) \] 这个式子要从右往左看,首先把 \(\min_{x}f(x, \lambda)\) 这一项理解成关于 \(\lambda\) 的函数 \(g(\lambda)\),然后再对 \(g\) 求最大值,即: \[ \begin{aligned} &g(\lambda) = \min_{x}f(x, \lambda)\\ &v = \max_\lambda{g(\lambda)} \end{aligned} \]
\(\inf\) 和 \(\sup\) 符号
\(\inf\) 是 infimum (下确界) 的简称,而 \(\sup\) 是 supremum (上确界) 的简称。它们和 min 还有 max 很相似,但是细节部分略有不同。具体来讲,一个例子足以:
有函数 \(\large f(x) = \frac{sin(x)}{x}\):
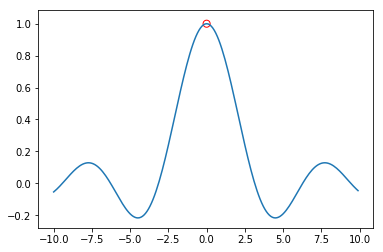
显然 \(f\) 在 0 处没有定义。那么:
- \(\max{f}\) 不存在
- \(\sup{f}\) 存在,且为1
其他符号
- \(dom\ f\): 函数 \(f\) 的定义域
- \(\bigcap S_i\): 对若干集合 \(S_i\) 求并集
2.2 凸函数和凹函数
关于这两个,我有一言请诸位静听:
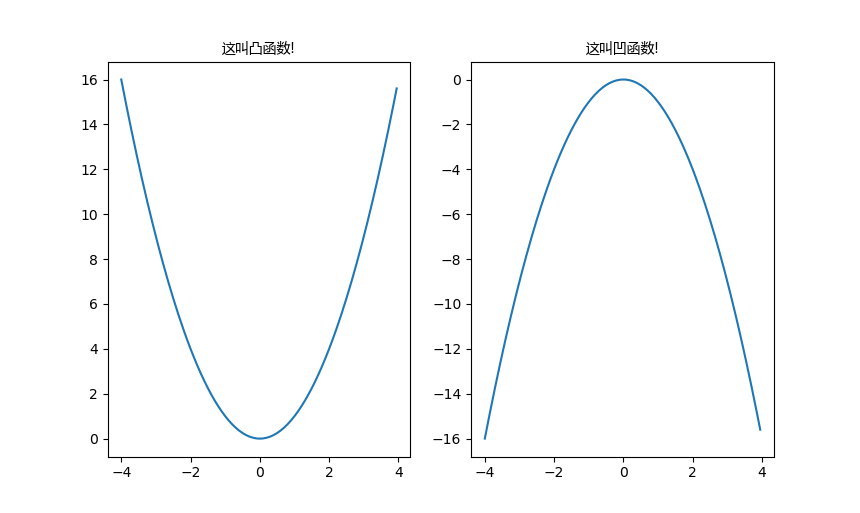
没错,其实是上凹下凸,这是国际惯例,我们国内的定义(也就是中学教的)是反过来的,我们在此后一律使用国际标准。
另外关于凸函数和凹函数有性质如下:
- 若函数 \(f: \mathbb{R^n} \to \mathbb{R}\) 是凸的,则:
\[ \begin{aligned} &\forall x,\ y \in dom\ f,\ \forall \theta \in [0, 1]\\ &f(\theta x + (1 - \theta)y) \leqslant \theta f(x) + (1 - \theta) f(y) \end{aligned} \]
- 若函数 \(f: \mathbb{R^n} \to \mathbb{R}\) 是凹的,则:
\[ \begin{aligned} &\forall x,\ y \in dom\ f,\ \forall \theta \in [0, 1]\\ &f(\theta x + (1 - \theta)y) \geqslant \theta f(x) + (1 - \theta) f(y) \end{aligned} \]
2.3 仿射函数
假如有 \(\vec{x} \in \mathbb{R^n}\), \(\vec{b} \in \mathbb{R^m}\), 矩阵 \(A_{m\times n}\),那么:
\[ \vec x \rightarrow A\vec x + \vec b \]
被称为 \(\mathbb{R^n} \rightarrow \mathbb{R^m}\) 的仿射变换,这一过程被称为仿射函数。 \[ f(x) = Ax + b,\ x\in \mathbb{R^n} \]
比如最简单的: \[ a_1x_1 + a_2x_2 + \cdots + a_nx_n + b \] 就是一个仿射函数。
仿射函数有一个非常重要的性质,那就是它既凹又凸,准确来讲在凹凸函数的那个不等式中,仿射函数是可以取等号的: \[ f(\theta x + (1 - \theta)y) = \theta f(x) + (1 - \theta) f(y) \] 这个证明很简单,自己都可以试试。
2.4 凸优化
我们在 1.3 节中的式 (1) 给出的式子其实是优化问题的基本形式: \[ \large \begin{aligned} &\min_{x \in \mathbb{R^n}}{f(x)}\\ &s.t \quad c_i(x) \leqslant 0, i \in [1, k]\\ &\qquad h_j(x) = 0, j \in [1, l]\\ \end{aligned} \]
而所谓的凸优化,是满足一些特定条件的优化问题,它要求:
- \(f(x)\) 是凸函数
- \(c_i(x)\) 是凸函数
- \(h_j(x)\) 是仿射函数
也就是 \[ \large \begin{aligned} &\min_{x \in \mathbb{R^n}}{f(x)}\\ &s.t \quad c_i(x) \leqslant 0, i \in [1, k]\\ &\qquad a_jx = b_j, j \in [1, l]\\ \end{aligned} \]
凸优化有一个重要的性质:任意位置的局部最优解同时也是全局最优解。
3. 从广义拉格朗日函数到拉格朗日对偶函数
OK,做了一大堆铺垫,我们终于要开始正式将拉格朗日对偶了。
首先来回忆一下我们的原问题 (Primal Problem): \[ \large \begin{aligned} &\min_{x \in \mathbb{R^n}}{f(x)}\\ &s.t \quad c_i(x) \leqslant 0, i \in [1, k]\\ &\qquad h_j(x) = 0, j \in [1, l]\\ \end{aligned} \tag{1} \]
首先我们做两个约定:
- 我们不假定原函数 \(f\) 的凹凸性,也就是 \(f\) 可以是非凸非凹函数
- 记问题的定义域 \(D = (dom\ f)\cap(\bigcap_{i=1}^k{c_i})\cap (\bigcap_{i=1}^l{h_i})\)
- \(D \not = \empty\)
- 我们约定最终求出来的最优结果用 \(p^*\) 表示
3.1 啥是对偶?
对于原问题(1)我们通常用拉格朗日对偶的方式来求解。啥是对偶?对偶说白了就是实质相同但从不同角度提出不同提法的一对问题。有时候原问题 (Primal Problem) 不太好解,但是对偶问题 (Dual Problem) 却很好解,我们就可以通过求解对偶问题来迂回地解答原问题。
在这里我们用的是拉格朗日对偶的方法来解决,既然我们说用对偶的方法的原因在于原问题不好解,那么这里也是如此吗?
当然了。
首先我们来看看原问题有什么难的地方:
- 约束条件太多
很显然约束越多,问题就越难解决,原问题中总共有 \(k + l\) 个约束,相当麻烦 - 原问题凹凸性不明确
之前我们说过,“不假定原函数 \(f\) 的凹凸性”,这就意味着我们无法将凸优化的方法应用在原问题中
那么它的拉格朗日对偶问题有什么优点呢?
- 只有一个约束
- 拉格朗日对偶问题一定是凹的
这里先做一个感性的认识,细节方面接下来慢慢说。
3.3 广义 Lagrange 函数
早前我们说过,对于等式约束问题可以用构建拉格朗日函数的方法来求解。这里也一样,我们可以为原问题构建一个广义拉格朗日函数 \(\mathcal{L}\):
\[ \begin{aligned} &\mathcal{L}: \mathbb{R^n}\times \mathbb{R^k}\times \mathbb{R^l} \rightarrow R\\ &\mathcal{L}(x, \lambda, \mu) = f(x) + \sum_{i = 1}^{k}{\lambda_ic_i(x)} + \sum_{j = 1}^{l}{\mu_jh_j(x)}\\ &\vec x \in \mathbb{R^n},\ \vec \lambda \in \mathbb{R^k},\ \vec \mu \in \mathbb{R^l} \end{aligned} \tag{2} \] \(\vec \lambda\) 和 \(\vec \mu\) 被称为拉格朗日乘子向量。
有了这个广义拉格朗日函数,现在我们分别可以定义另外对偶函数 \(g\)。
3.4 Lagrange 对偶函数 \(g\)
我们可以根据 \(\mathcal{L}\) 定义一个拉格朗日对偶函数 (Lagrange Dual Function) \(g(\lambda, \mu)\):
\[ \begin{aligned} &&g(\lambda, \mu) &= \inf_{x\in D}{\mathcal{L}(x, \lambda, \mu)}\\ &&\ &=\inf_{x\in D}{\big (f(x) + \sum_{i = 1}^{k}{\lambda_ic_i(x)} + \sum_{j = 1}^{l}{\mu_jh_j(x)}\big )}\\ &&\lambda \geqslant 0 \end{aligned} \tag{3} \]
注意到 \(\lambda \geqslant 0\) 这个要求,为什么会有这么一个要求我们下一节讲,现在先看一些别的。
这个对偶函数 \(g\) 有一个非常重要的性质:它一定是一个凹函数,我们可以证明一下。
首先我们明确一个凹函数具有性质: \[ f(\theta x + (1 - \theta)y) \geqslant \theta f(x) + (1 - \theta) f(y) \] 要证明 \(g\) 是一个凹函数就是要证明它满足这个不等式。
- 第一步
我们首先记: \[ g(\lambda, \mu) = \inf_{x\in D}\{\mathcal{L}(x_1, \lambda, \mu), \mathcal{L}(x_2, \lambda, \mu), \cdots, \mathcal{L}(x_n, \lambda, \mu)\}, x\to +\infty \]
这个好理解,我是就是把 \(g\) 看作一个逐点求下界的无穷集合。
- 第二步
简记: \[ \gamma = (\lambda, \mu),\ g(\gamma) = g(\lambda, \mu) \] 这个主要是为了一会推导的时候方便写。
- 第三步
证明过程如下: \[ \begin{aligned} &g(\theta\gamma_1 + (1 - \theta)\gamma_2)\\ &= \inf\{\mathcal{L}(x_1, \theta\gamma_1 + (1 - \theta)\gamma_2),\ \mathcal{L}(x_2, \theta\gamma_1 + (1 - \theta)\gamma_2),\ \cdots,\ \mathcal{L}(x_n, \theta\gamma_1 + (1 - \theta)\gamma_2)\}\\ &\geqslant \inf\{\theta\mathcal{L}(x_1, \gamma_1) + (1-\theta)\mathcal{L}(x_1, \gamma_2),\ \cdots,\ \theta\mathcal{L}(x_n, \gamma_1) + (1-\theta)\mathcal{L}(x_n, \gamma_2)\}\\ &\geqslant\theta\inf\{\mathcal{L}(x_1, \gamma_1),\ \mathcal{L}(x_2, \gamma_1), \cdots,\ \mathcal{L}(x_n, \gamma_1)\} + (1 - \theta)\inf\{\mathcal{L}(x_1, \gamma_2),\ \mathcal{L}(x_2, \gamma_2), \cdots,\ \mathcal{L}(x_n, \gamma_2)\}\\ &=\theta g(\gamma_1) + (1 - \theta)g(\gamma_2) \end{aligned} \]
来逐行解释一下:
- 第一行:之前讲过了,略
第二行
注意到 \(\mathcal{L}(x_i, \gamma)\) 中,\(x_i\) 的值已经固定了,\(\therefore f(x),\ c_i(x),\ h_i(x)\) 都是常数,我们分别记为 \(r, p, q\)。则: \[ \mathcal{L}(x_i, \gamma) = \sum{\lambda_i p_i} + \sum{\mu_j q_j} + r \] 显然,\(\mathcal{L}\) 是一个仿射函数,而我们知道仿射函数又凸又凹,所以有: \[ \mathcal{L}(x_n, \theta\gamma_1 + (1 - \theta)\gamma_2) \geqslant \theta \mathcal{L}(x_n, \gamma_1) + (1 - \theta) \mathcal{L}(x_n, \gamma_2) \] 整理一下,就有了第二行。第三行
从第二行到第三行,运用了一个简单的数学原理: \[ min\{a_i + b_i\} \geqslant min\{a\} + min\{b\} \]
总结: 不管原函数 \(f\) 的凹凸性,它的对偶函数 \(g\) 一定是凹函数
3.5 对偶函数与原函数的关系
我们之所以需要这么一个对偶函数是因为 \(g\) 有一个非常重要的作用,引用一句《凸优化》原文的句子:
Give the lower bound on optimal value (\(p^*\))
什么意思呢?其实这是 Dual Function 一个很重要的性质: \[ \forall \lambda \geqslant 0 \Rightarrow g(\lambda, \mu) \leqslant p^* \tag{4} \] 换而言之,只要 \(\lambda\) 不小于0,\(g\) 的值用于不会超过 \(p^*\)!
要证明这个定理并不难,我们首先假设 \(\hat x \in D\) 是原问题的一个可行解:
\[ \begin{aligned} & \because c_i(\hat x) \leqslant 0,\ h_i(\hat x) = 0\\ & \therefore \lambda_ic_i \leqslant 0, \mu_ih_i = 0\\ & \therefore \mathcal{L}(\hat x, \lambda, \mu) = f(x) + \sum_{i = 1}^{k}{\lambda_ic_i(\hat x)} + \sum_{j = 1}^{l}{\mu_jh_j(\hat x)} \leqslant f(x)\\ & \text{Meanwhile}\quad g(\lambda, \mu) = \inf{\mathcal{L}},\quad p^* = \min f\\ & \therefore g(\lambda, \mu) \leqslant \mathcal{L} \leqslant p^* \end{aligned} \]
这给了我们一个重要的启示,无论如何,\(p^*\) 都不会小于 \(\max{g(\lambda, \mu)}\)。
4. 从原问题到拉格朗日对偶问题
在此之前,我们讲了原问题,讲了广义拉格朗日函数和拉格朗日对偶函数,又讲了这两个之间的关系。那么这有什么用呢?
用处当然很大啦!现在我们不妨这么一想,既然 Lagrange 对偶函数给出了最优解 \(p^*\) 的下界,那么请问:
What is the best lower bound that can be obtained from lagrange dual function?
啥意思?我们来捋一捋:
- 首先我们明确一件事,我们的目的是找到最优解 \(p^*\)
- 有时候 \(p^*\) 其实并不一定能解出来,这种情况下,我们希望可以给出一个尽可能地逼近 \(p^*\) 的值
- 既然我们已经知道了 \(g\) 可以给出下界,那么那个值能够尽可能逼近呢?
- 答案是: \(\max g(\lambda, \mu)\) (\(s.t\ \lambda \geqslant 0\))
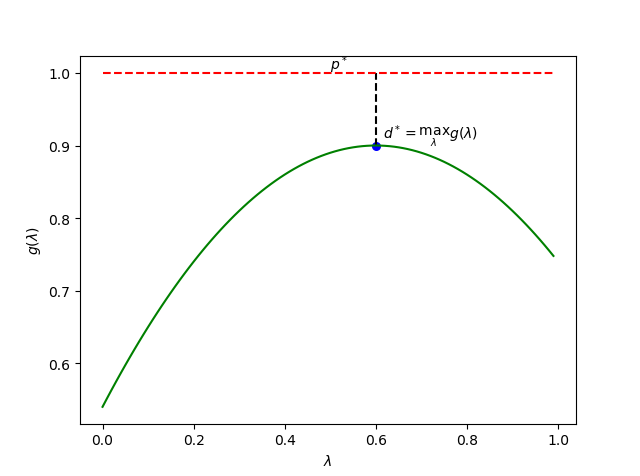
明白了这一点,我们终于可以介绍拉格朗日对偶问题了。
首先再次回顾一下原问题。 \[ \large \text{Primal Problem}\\ \begin{aligned} \\ &\min_{x \in \mathbb{R^n}}{f(x)}\\ &s.t \quad c_i(x) \leqslant 0, i \in [1, k]\\ &\qquad h_j(x) = 0, j \in [1, l]\\ \end{aligned} \tag{1} \] 然后隆重介绍对偶问题的形式。 \[ \large \text{Lagrange Dual Problem}\\ \begin{aligned} \\ &\max_{\lambda, \mu}g(\lambda, \mu) = \max_{\lambda, \mu}\inf_{x\in D}{\mathcal{L}(x, \lambda, \mu)}\\ &s.t \quad \lambda_i \geqslant 0,\ i = 1, 2,\dots, k\\ \end{aligned} \tag{5} \]
参考上面那幅图,其实这个所谓的对偶问题在干什么已经很清楚了。我们把问题 (1) 的结果令为 \(p^*\),而问题 (5) 的结果记为 \(d^*\)。
现在回顾一下之前说的求解对偶问题的好处,我们再来看看为什么需要拉格朗日对偶。
首先是问题 (1) 有哪些 annoying 的地方: 1. 原问题的约束太多了,又是等式又是不等式 2. 问题 (1) 不一定是一个凸优化问题,所以即便找到了貌似是 \(p^*\) 的点,也很可能不过是个局部最优点。
那 Lagrange 对偶问题 (5) 就好一些吗?还真是,我们来康康:
- 约束少了,这是很明显的,少了 \(l\) 个,而且剩下的 \(k\) 个约束也比原来的简单一些
- 最最重要的,问题 (5) 一定是一个凸优化问题,所以很多凸优化的手段全可以用上了
总结一下就是:
我们希望求 \(p^*\),但是 \(p^*\) 实在不好求,所以退而求其次去求 \(d^*\),这个就好求多了。
并且由于 \(d^* \leqslant p^*\),我们在求出了 \(d^*\) 后即便不能得到 \(p^*\),也可以得到 \(p^*\) 的下界;而在一些非常理想的情况下,\(d^* = p^*\)。
\(d^* = p^*\)?如果真能这样那简直就是天堂了,显然一般情况下这两个是不同的,但是在满足某些特殊条件时,这个等式就可以成立了。具体这些条件是什么,我们在接下来的几节里再来谈谈。
5. 弱对偶与强对偶
5.1 弱对偶
所谓强弱对偶,指的是 Lagrange 对偶问题的一种性质,关于弱对偶我们其实在前面已经谈到了。
\[ d^* \leqslant p^* \tag{6} \]
即便原文题不是凸问题,上述的不等式也成立,这就是所谓的弱对偶性 (Weak Dulity)。这样的性质即便是 \(d^*\) \(p^*\) 无限时也成立,也就是说:
- 如果 \(p^* = -\infty\),则 \(d^* = -\infty\)
- 如果 \(d^* = +\infty\),则 \(p^* = +\infty\)
我们还把 \(p^* - d^*\) 称为最优对偶间隙 (Optimal Duality Gap),这个值必然非负。
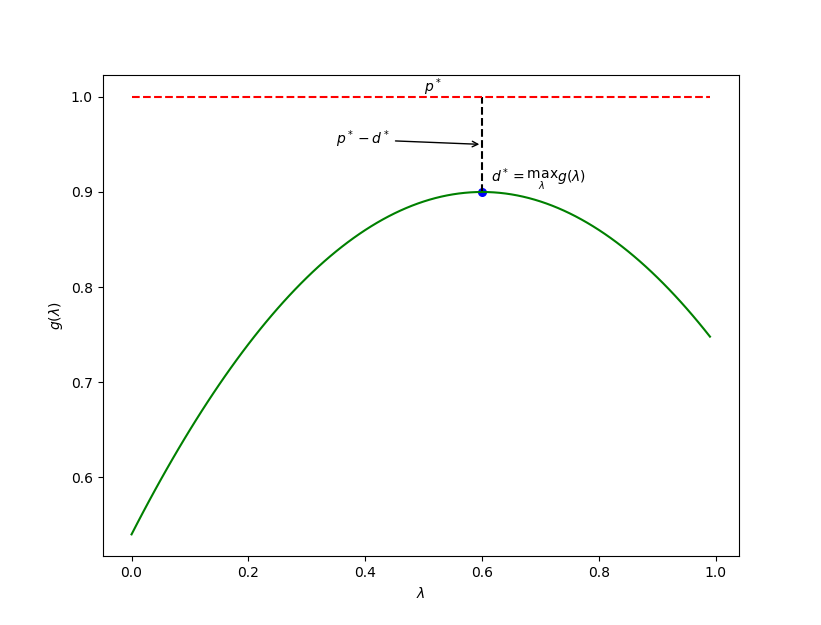
5.2 强对偶
对于式子 (6) 还有一种很特殊的情况:
\[ d^* = p^* \tag{7} \]
这种情况,我们称之为强对偶性 (Strong Duality)。
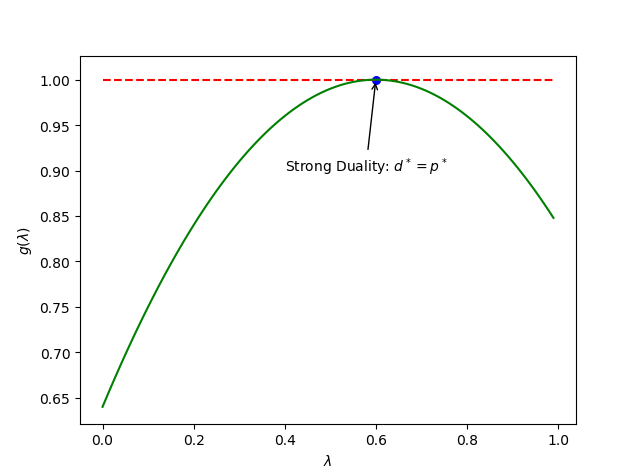
之所以称之为“强”对偶,正是因为这种性质相对于“弱”对偶而言对我们的意义更加重大。很显然,当我们待求解的问题是强对偶的话,那就意味着我们通过对偶问题求的的解就不再仅仅是原问题解的一个下界了,而是 \(p^*\) 本身。用人话来讲就是:
如果满足强对偶,那只要我们求出了 \(d^*\) ,我们就知道了 \(p^*\) 的值
显然,强对偶并不是什么时候都成立的,必须要满足一定的条件才会有强对偶这种东西。
下一节,我们着重讲解这些条件是什么 (充分条件、必要条件)。
6. 关于强对偶和最优的一些条件
首先要明确一件事情:使满足强对偶的条件有很多种,我们这里只介绍最基本的。
6.1 Convex + Slater
如果:
- 原问题是凸优化
- 满足 Slater 条件
则一定满足强对偶
注: 这是强对偶的一个充分条件
下面具体解释一下含义。
首先是第 1 点,在 2.4 节中我们讲到过,这意味着:
- \(f(x)\) 是凸函数
- \(c_i(x)\) 是凸函数
- \(h_j(x)\) 是仿射函数
再来看看第 2 点,所谓的 Slater 条件。严格的 Slater 条件表述如下: \[ \begin{aligned} &\exists x \in D\\ &c_i(x) < 0, i \in [1,k]\\ &Ax = b \end{aligned} \tag{8} \] 其中 \(Ax = b\) 是把 \(a_jx=b_j\) 合起来写的写法,我们的主要关注点在 \(c_i\) 上。我们把满足该条件的点称为是严格可行的,因为不等式约束要求严格成立。
之所以称上述的 Slater 条件是严格的,是因为 Slater 还有一个弱化的版本。
\[ \begin{aligned} &\text{若}c_i(x)\text{是仿射函数},\ i = [1, p] \And p \leqslant k\\ &\text{则弱化的 Slater 条件为:}\\ &\exists x \in D\\ &c_i(x) \leqslant 0, i \in [1,p]\\ &c_i(x) < 0, i \in [p+1, k]\\ &Ax = b \end{aligned} \tag{9} \]
任意满足: 1. 凸优化 2. 强或弱 Slater 条件
的优化问题同样满足强对偶性 (充分条件)。
6.2 KKT 条件
有必要明确一些很重要的点。
首先是 KKT 条件实际上应该分为两种情况讨论:
- Case 1: 原问题为非凸问题情况下的 KKT
- Case 2: 原问题为凸问题情况下的 KKT
为什么要分两点来讨论?因为在两种情况下,KKT 条件作为一个“条件”的充分性和必要性是不同的,自然用法也不同。
再有一个问题是,无论哪种情况,KKT 都是着眼于“最优解”这个议题进行讨论的。
下面分两种情况讨论。
6.2.1 非凸问题下的 KKT
当原问题并非凸优化(或者不清楚、不关心是不是凸优化)时,KKT 条件是一种用来描述强对偶情况下最优解性质的条件
换而言之,若强对偶性质成立,那么满足最优解的点一定满足 KKT 条件;KKT 条件是强对偶一个必要条件,但无法作为充分条件来使用
我们首先给出 KKT 条件的具体数学描述,然后逐行解释。
假设: 1. 原问题中的函数均可微 2. 强对偶成立 3. \(x^*\) 和 \((\lambda^*, \mu^*)\) 分别为原问题和对偶问题的某对最优解
则: \[ \begin{aligned} &c_i(x^*) \leqslant 0 &i = 1, \dots, k\\ &h_i(x^*) = 0 &i = 1, \dots, l\\ &\lambda_i^* \geqslant 0 &i = 1, \dots, k\\ &\lambda_i^*c_i(x^*) = 0 &i = 1, \dots, k\\ &\nabla f(x^*) + \sum_{i=1}^{k}\lambda_i^*\nabla c_i(x^*) + \sum_{i=1}^{l}\mu_i^*\nabla h_i(x^*) = 0 \end{aligned} \]
这就是 KKT 条件了,第一行和第二行是原问题的约束,必须遵守;第三行则是弱对偶的必要条件。最后一行,我们知道,既然 \(x^*\) 是最优点,那么理所当然的,原问题 \(\mathcal{L}\) 关于 \(x^*\) 的导数必须等于 0。
现在难点主要在第四行,其实第四行的不等式是一个被称为“互补松弛条件”的东西。我们做一个简单的证明。
首先我们知道 \[ \begin{aligned} &&f(x^*) &= g(\lambda^*, \mu^*)\\ && &= \inf_{x}{\mathcal{L}(x^*, \lambda^*, \mu^*)}\\ \end{aligned} \] 所以有: \[ \begin{aligned} &&f(x^*) &\leqslant \mathcal{L}(x^*, \lambda^*, \mu^*)\\ && &= f(x^*) + \sum_{i=1}^{k}\lambda_i^*c_i(x^*) + \sum_{i=1}^{l}\mu_i^*h_i(x^*) \end{aligned} \] 同时我们知道,\(\lambda \geqslant 0\) 且 \(c_i(x) \leqslant 0\),而 \(h_i = 0\),所以有: \[ f(x^*) + \sum_{i=1}^{k}\lambda_i^*c_i(x^*) + \sum_{i=1}^{l}\mu_i^*h_i(x^*) \leqslant f(x^*) \] 联立上面几个式子,有: \[ \begin{aligned} &&f(x^*) &= g(\lambda^*, \mu^*)\\ && &= \inf_{x}{f(x^*) + \sum_{i=1}^{k}\lambda_i^*c_i(x^*) + \sum_{i=1}^{l}\mu_i^*h_i(x^*)}\\ && &= f(x^*) + \sum_{i=1}^{k}\lambda_i^*c_i(x^*) + \sum_{i=1}^{l}\mu_i^*h_i(x^*)\\ && &= f(x^*) \end{aligned} \] 注意到第二行和第三行想等,而 \(\lambda_ic_i \leqslant 0\),所以为了让等式成立,必然有: \[ \lambda_ic_i(x) = 0 \] 这被称为互补松弛条件。
把这几个条件一股脑叠加在一起,就构成了 KKT 条件。对于目标函数和约束函数可微的优化问题,如果强对偶成立,则任意一对原问题的最优解和对偶问题的最优解满足 KKT 条件。
6.2.2 凸问题下的 KKT
当原问题为凸优化时,KKT 条件在非凸的基础上有多了找到最优点的功能
在这种情况下,那么满足 KKT 条件的点一定是原问题和对偶问题的最优解;KKT 条件成了强对偶和最优解的充要条件
也就是说: 1. 若原问题是Convex的 2. \(\exists \hat x, \hat \lambda, \hat \mu\) 满足: \[ \begin{aligned} &c_i(\hat x) \leqslant 0 &i = 1, \dots, k\\ &h_i(\hat x) = 0 &i = 1, \dots, l\\ &\hat \lambda_i \geqslant 0 &i = 1, \dots, k\\ &\hat \lambda_i c_i(\hat x) = 0 &i = 1, \dots, k\\ &\nabla f(\hat x) + \sum_{i=1}^{k}\hat \lambda_i \nabla c_i(\hat x) + \sum_{i=1}^{l}\hat\mu_i \nabla h_i(\hat x) = 0 \end{aligned} \]
那么 \(\hat x\) 和 \((\hat \lambda, \hat \mu)\) 分别是原问题和对偶问题的最优解,且最优对偶间隙为 0,强对偶性满足。
6.3 几种条件之间的关系的总结
对于任意问题
强对偶 + 最优解 \(\Rightarrow\) KKT条件对于 Convex + 可微 的问题
KKT 条件 \(\Rightarrow\) 强对偶 + 最优解Convex + Slater \(\Rightarrow\) 强对偶