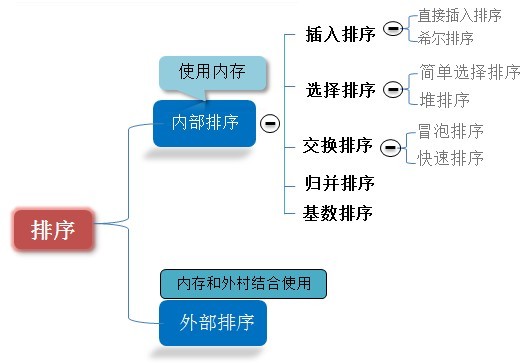
术语
- 数据表( data list):
它是待排序数据对象的有限集合。 排序码(key):
通常数据对象有多个属性域,即多个数据成员组成,其中有一个属性域可用来区分对象,作为排序依据。该域即为排序码。每个数据表用哪个属性域作为排序码,要视具体的应用需要而定。- 稳定: 如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
不稳定:
如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;- 内排序:
所有排序操作都在内存中完成; 外排序:
由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;- 时间复杂度: 一个算法执行所耗费的时间。
空间复杂度: 运行完一个程序所需内存的大小。
比较
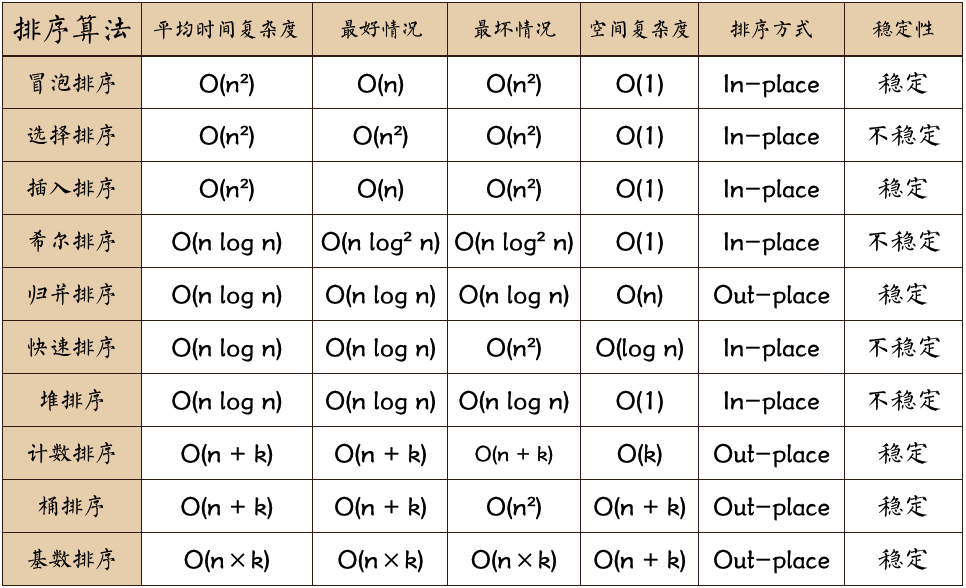
说明一下,表内除了最后三个以外都是基于比较的排序,而基于比较的排序最快也无法超越 \(n\log_{}n\)。
n: 数据规模k:“桶”的个数In-place: 占用常数内存,不占用额外内存Out-place: 占用额外内存
当需要对大量数据进行排序时,In-place sort就显示出优点,因为只需要占用常数的内存。
设想一下,如果要对10000个数据排序,如果使用了Out-place sort,则假设需要用200G的额外空间,则一台老式电脑会吃不消,但是如果使用In-place sort,则不需要花费额外内存。