关于字符串的模式匹配问题,有许多算法,这里先介绍最简单著名的两个。
1. 暴力求解
一个简单粗暴的方法就是,从主串的第一个字符和模式串的第一个字符开始,一个一个字符匹配。一旦失配,就从该次匹配开始时匹配的主串字符的下一个字符开始重新匹配。
1 | int BruteForce(const string &src, const string &pattern) |
时间复杂度分析:
令主串长n,模式串长m。则: - 最好:开头位置就匹配成功了,所以为 \(O(m)\) - 最坏:根本匹配不成功,结果为 \(O(m\times n)\)
2. KMP算法
2.1 对蛮力算法的反思
以上的蛮力算法的低效的原因在于对主串中每个字符都进行了大量的重复性比较。最糟糕的情况下,主串中的任意一个字符可能会和模式串中的每一个字符都比较一次。就好比运用递归计算斐波那契数列一样,过多的重复计算比对大大拖慢了算法。 不妨来考察一下最坏的情况:
\[ 000000...001\\ 0001 \]
如果要匹配以上两个字符串的话,就会陷入到最坏的情况。但是为什么会这样呢?进过分析,我们可以看出,主要是因为在模式串中存在大量与主串匹配的前缀,所以大量地出现“在最后一个字符的位置失配导致不得不从头再来”的情况。
2.2 新算法的提出
事实上,大量重复的比较是可以避免的。首先我们要注意到一个问题:在任何一个时刻,当前正在比对的模式串字符之前的前缀串和对应的主串中的子串是完全相等的。所以我们要想法设法将这些信息“存储”起来,为后面的比对所用。
那么储存起来又该干什么用呢?
不妨这样来考虑,之前我们在蛮力求解的算法中,每次失配,都要重新移动主串指针和模式串的指针并进行重新比对。可是,我们不妨换条思路:既然之前比对过的主串的信息已经知道了,不妨将主串的指针定住不动,只移动模式串的指针。

以上图为例,我们让主串的比对字符仍为空格符,向右滑动模式串,使得模式串中的另外一个继任字符继续和空格符比对,在这里这个继任字符是 'C'。

那么,如何找到这个字符呢?换而言之,如何确定模式串要向右滑动几个单位呢?注意到一点:在这个继任字符之前的前缀子串必须和主串对应位置相配。
譬如在这里我们就发现,在移动前主串的部分匹配子串的后缀 AB 正好和模式串的前缀 AB 匹配,所以我们向右滑动模式串直到两组 AB 对齐。
如何知道该滑动几位?这里就要借助到我们之前所说的储存起来了的主串的部分匹配的部分了。不过要注意到,那部分匹配的区域是和模式串的部分匹配前缀相同的,所以与其说是存储了主串的信息,倒不如说是储存模式串信息并间接地分析出主串的信息。
方法在于,我们要事先构造出一个 next 数组,它记录了模式串的每个字符的某种信息。每当适配的时候,通过执行 patPtr = next[patPtr] 来得到下一次应该匹配的继任字符,从而实现了模式串的右滑。
现在来讨论一下这个 next 数组有什么要求。根据我们之前的分析我们可以得出一个结论,next[patPtr] 必然满足这样以下条件:
next[patPtr]所指向的字符之前的前缀子串必然与patPtr之前的子串的某个后缀是匹配的,这样他就能满足我们之前说的“继任字符之前的前缀子串必须和主串对应位置相配”的要求。
通俗地讲就是:2
- 令
pattern[0:patPtr]为 s1 - 令
pattern[0:next[patPtr]]为 s2 - s1 的某个后缀子串 == s2
又因为 pattern 串的任何一个前缀子串必然从第一个字符开始,所以 next[patPtr] 所指向的字符的索引值一定等于该字符之前的前缀子串的长度。
也就是说,如果字符串的索引是从 0 开始的话,那么 next[patPtr] 值是代表着字符 pattern[patPtr] 之前的子串的真前缀与真后缀相同的最大长度(真前缀表示长度至少为 1 的前缀,因为空串也算前缀)。
不过还有一个小问题,如果在第一个字符就失配了怎么办?为此,我们不妨令 next[0] 为 -1,也就是假设存在一个虚拟的哨兵头结点,我们假设这个哨兵结点是一个通配符,这样就保持了逻辑的一致性。

2.3 KMP的初步框架
至此,我们已经可以构建出KMP算法的大体框架了: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20int KMPMatch(const string &src, const string &pattern)
{
const int srcLen = src.length(), patLen = pattern.length();
int srcPtr = 0, patPtr = 0;
int next[patLen];
ConstructNext(pattern, next);
while (srcPtr < srcLen && patPtr < patLen)
{
//后面一个部分好理解,前面的 -1 主要是我们会把 next[0] 设置为 -1
//这样即使在第一个字符就失配了,patPtr 也可以变成 0 然后继续和下一个字符进行比较
if (patPtr == -1 || src[srcPtr] == pattern[patPtr])
{
++srcPtr;
++patPtr;
}
else
patPtr = next[patPtr];
}
return (patPtr == patLen)? srcPtr - patPtr : -1;
}
可以看出,算法在一个循环当中进行,每次有两种分支情况: - 匹配 - 正常的字符匹配
比较下一位字符 - 虚拟的通配符匹配
逻辑上是比较哨兵字符的下一位,实质上就是从新开始比较 - 不匹配
将模式串右滑,一直滑到继任字符
注意不要用 size_t,因为这里i是可以等于-1的。
下面我们来考虑如何构造 next 数组。
2.4 构造 next
我们大可不必真的去对每个子串求最大匹配的真前缀和真后缀的长度,实际上,我们可以通过递推的方式来进行求取。
首先我们有如下结论:
\[ next[i] \leqslant i \]
这当然是利索当然的了,next[i] 是在找前缀,所以肯定至少不会比 i 还大。
另外:
\[ next[j+1] \leqslant next[j] + 1 \]
对于 j + 1而言,最好的情况不过是 pattern[j] == pattern[next[j]],也只有在这种情况下才能取等号。
现在我们开始讨论已知 \(next[i]\) 如何求 \(next[i+1]\)
假设当前 next[i] 的值为 t,这就说明:
\[ p_{0}p_{1}\cdots p_{t-1} = p_{i-t}p_{i-t+1}\cdots p_{i-1} \]
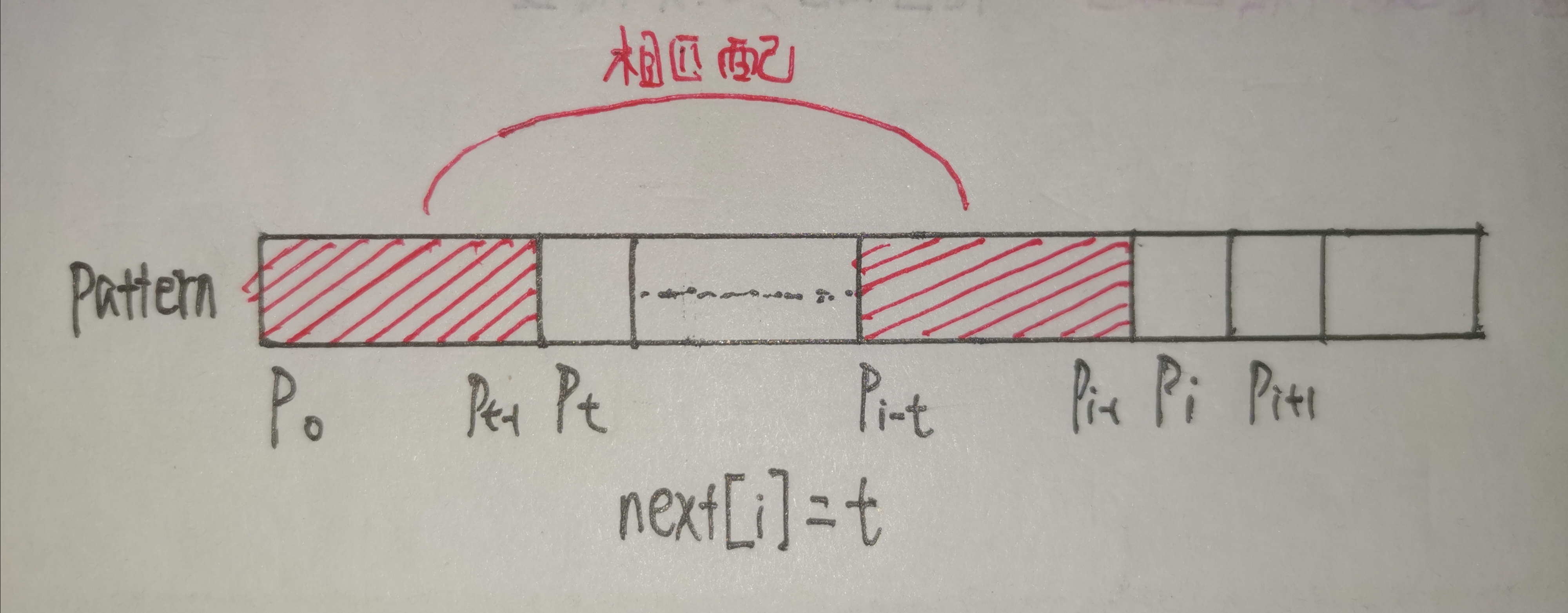
现在分两种情况讨论:
2.3.1 Case 1:如果p[i] == p[t]
显然这就意味着:
\[ p_{0}p_{1}\cdots p_{t-1}p_{k} = p_{i-t}p_{i-t+1}\cdots p_{i-1}p_{i} \]
稍加思考就可以看出,这种情况下next[i+1] = t+1
比如对于:
a b b c a b a c
-1 0 0 0 0 1 2 1
第二个a的next为0,且p[0]也为a,所以第三个b的next一定为1
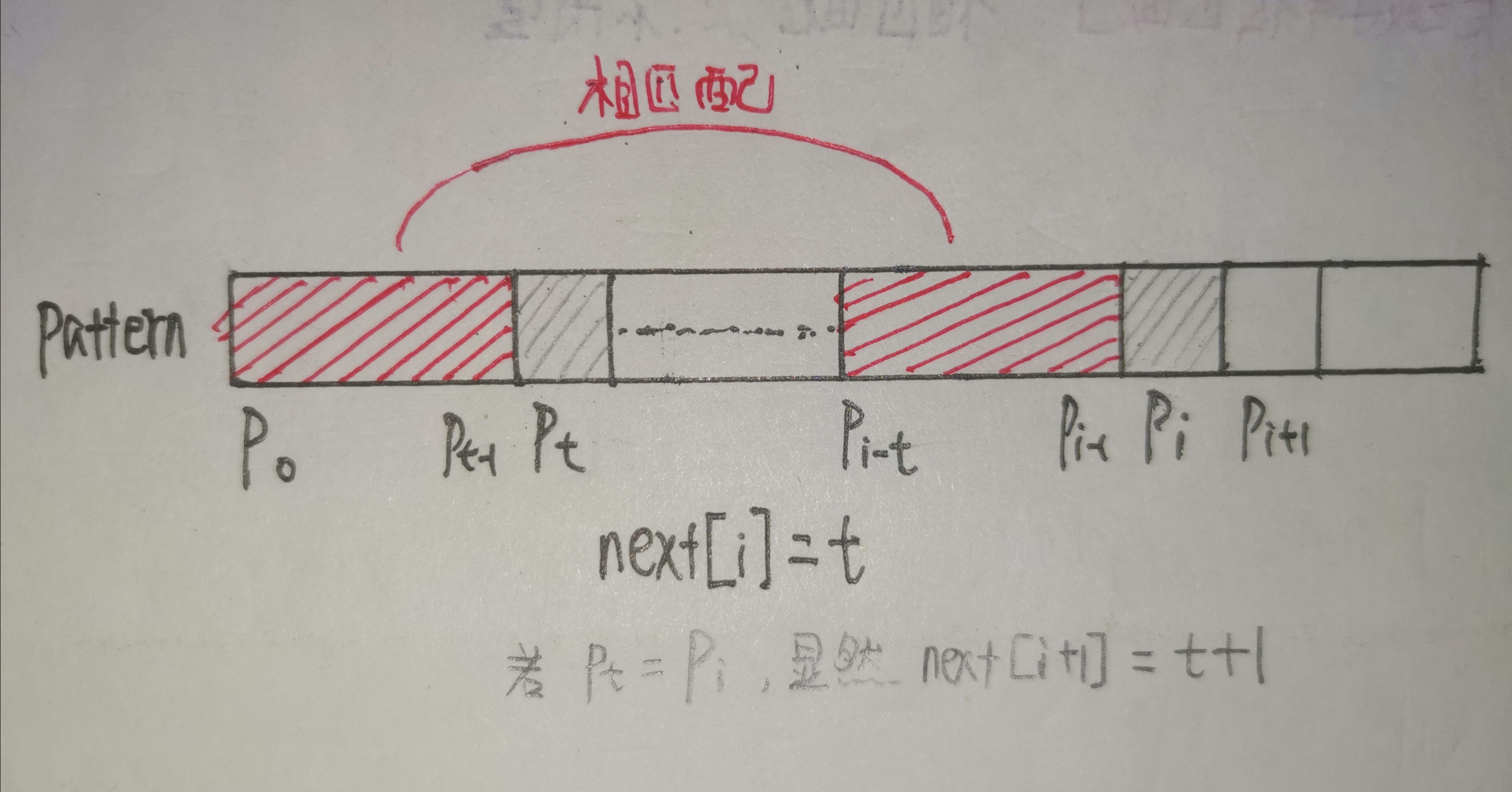
2.3.2 Case 2: 如果p[i] != p[t]
这种情况就较为复杂了,我们需要先仔细考虑一下我们需要干什么。正如前面分析过的,当我们求 next[i+1] 时我们希望找到一个继任字符 (令为k),使这个字符前的长度为 k 的前缀子串和紧挨着 p[i+1] 前面的长度为 k 的后缀子串匹配。
不妨分两步考虑,令 k 前面那个字符为tx。则必然有 p[0, tx) == p[i-tx, i)且 p[tx] == p[i]。
p[0, tx) == p[i-tx, i)
我们仔细考虑一下就会发现,这和我们在KMP主算法中遇到的问题不正是样的吗?所以我们不妨把求 next 数组的问题看作是另一个模式匹配的问题,只不过在这里整个模式串既是主串又是模式串。更准确的而言,我们要把当前需要匹配的 p[i] 附近当作是主串,p[tx] 附近当作是模式串。
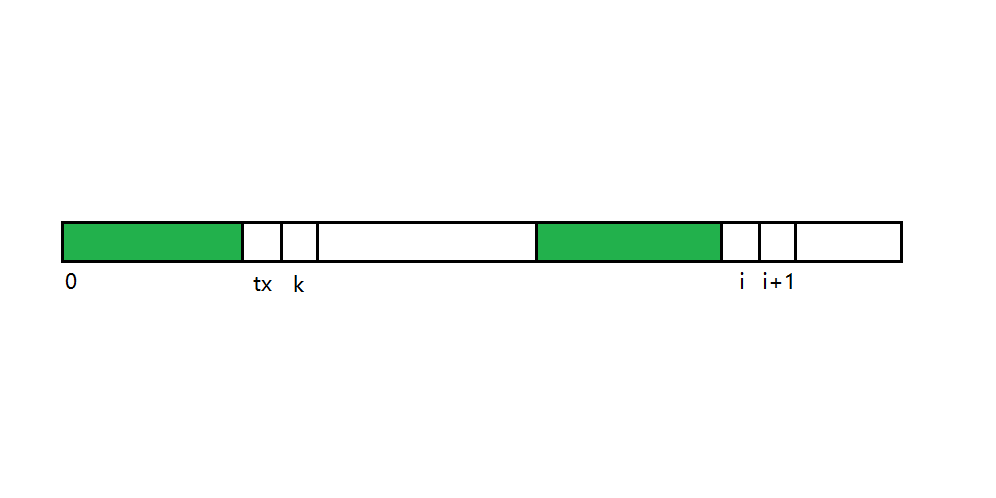
我们想找到 i + 1 对应的 tx,就类似地等价与 KMP 中 p[i] 在和 p[tx] 比较时失配的情况。很简单,只需要右移模式串,直到两个前缀相等时即可。符合要求的位置有哪些呢?显然,next[i]是符合这个要求的,但同时需要注意,next[next[i]]也是符合这个要求的,以此类推next[next[...next[i]]]也都符合要求。唯一不同的是,随着层次的推移,相同前缀子串的长度也不断减少。
总结以上的内容,我们可以得出一下结论:
令 t = next[i],通过不断的迭代 t= next[t] N次(N=0, 1, 2...),我们可以得到 N+1 个位置 t,它们能都满足 p[0, tx) == p[i-tx, i)。换而言之如果存在一个 tx 满足 p[0, tx] == p[i-tx, i] 那么这个tx 必然在这N+1个 t 中产生。
p[tx] == p[i]

既然已经知道了tx的取样范围,那么剩下的就好办了。既然i是固定不变的,那我们可以使用一个额外的变量lastNext(原谅我的取名水平),它记录的是上一个next[]的值。
通过不断向前迭代(lastNext = next[lastNext]),依次取得之前所说的 tx 值并每次和p[i]进行比较。
如果存在
p[lastNext] == p[i],那就恰好满足了我们的要求:如果不存在这样的字符,那么我们同样依靠虚拟的通配符哨兵位,假设存在这样一个能与任何字符匹配的结点。
在找到了我们的目标位置 tx 之后显然这就转化为了p[i] = p[t]的情况,因此我们就可以将next[i+1]填入 k = tx + 1 的值了。
2.4 next实现
1 | void ConstructNext(const string &pattern, int next[]) |
程序分析:
- 循环次数
可以看到我们在一开始先将 next[0] 填充,因此后续程序的循环次数应该为length - 1次而非length次。
ptr
每一轮循环,ptr 都指向 next 数组已经填好了的部分的最后一位。换而言之如果某次循环 ptr 的值为 x,那么本次循环的目的是求得 next[x+1]。程序一直进行到 ptr == p.length() - 2,也就是指向倒数第二位,在这一组(注意并不是每次循环就填好一个数组位置,有些循环是用来计算 lastNext 的)循环中,我们将next的最后一位填好,退出程序。
lastNext
相对的,lastNext指向的是“上一次”next[]数组的值。
- 条件分支
- 若匹配
匹配的情况有两种:一种是真匹配,一种是通配符匹配。
巧妙的是,无论是哪种情况我们都可以用同一种语句来处理。- 对于前者,
next[++ptr] = ++lastNext;代表了next[ptr+1] = next[ptr] + 1。注意原本lastNext代表的是next[ptr]的值,在执行后,它代表next[ptr+1]的值。 - 对与后者,由于此时
lastNext必定为-1,所以执行操作后恰好为next[ptr+1] = 0,即重新开始比对。
- 对于前者,
- 若不匹配
此时就开始了我们之前分析过的跳转流程:lastNext在每进行一次循环后都向上一次的"lastlastNext" 跳转。
只沿着next跳转保证了前缀除了最后一个字符的部分必然匹配;
每次循环都做一次pattern[ptr] == pattern[lastNext]的判断是为了找出使前缀最后一个字符也匹配的位置。
等到找到了这个位置后(不管是真匹配还是通配符匹配),**就跳入了if语句块,从而填写好next[ptr+1]的值。
- 若匹配
2.5 再优化
事实上以上的KMP算法版本还是有缺陷的。不妨来考虑这个例子:

之前的KMP算法会怎么处理这种情况?显然它会先把 j 移到2,发现不匹配;再把 j 移到1,又不匹配···最后一只移到了-1,才结束对本次主串中的字符1的匹配。
但是我们仔细分析就会发现这是没有必要的!原因在于 p[j] == p[next[j]] == p[next[next[j]]]...,所以如果 p[j] 不和 src[i]匹配,那么p[next[j]]也必定不和src[i]匹配,模式串注定要继续后移。
通过以上的分析,我们就可以发现,要想优化算法,就需要优化next表的构成。
1 | void ConstructNext(const string &pattern, int next[]) |
注意在这里我们不再简单地next[++ptr] = ++lastNext。而是增加了判断pattern[lastNext] == patern[ptr]:不相等一切好说;如果相等,就把它移到不相等的位置。
等等,相等时为什么是next[ptr] = next[lastNext]?为什么这样的赋值可以保证p[i] != p[next[pi]]?这是因为 next 表是从左到右建立的,所以如果其中一个位置 k 是已经建立好了的,那么必然满足p[k] != p[next[k]]。考虑到lastNext必然在 i 的左侧,所以 p[lastNext] 必然满足以上性质。因此若 p[i] == p[lastNext],则 p[i] 必然不等于 p[next[lastNext]]。(可以联想到我们在插入排序中,左侧的区间段必定是有序的这样一个考虑)
2.6 附:手工求next数组
- 步骤一:求
pattern的部分匹配表
比如对于这个模式串
> a b b c a b a c
假设部分匹配表为 pm,那么 pm[i] 表示以 pattern[i] 为结尾的子串和以 pattern[0] 为开头的子串相匹配的最大位数,比如上述子串对应的部分匹配表如下
a b b c a b a c
0 0 0 0 1 2 1 0
- 步骤二:将部分匹配表整体右移,首位用-1代替
a b b c a b a c
-1 0 0 0 0 1 2 1
当然这是指索引从0开始的情况,如果索引从k开始,那最后结果整体加上k。
3. 小注意
并不是说有了KMP等高效算法就无需管BF算法了。
举个例子,事实上Java中indexOf方法就是用BF实现的。
JDK的编写者们认为大多数情况下,字符串都不长,使用原始实现可能代价更低。因为KMP和Boyer-Moore算法都需要预先计算处理来获得辅助数组,需要一定的时间和空间,这可能在短字符串查找中相比较原始实现耗费更大的代价。而且一般大字符串查找时,程序员们也会使用其它特定的数据结构,查找起来更简单。这有点类似于排除特定情况下的快速排序了。
所以也不是越快越好。
4. 扩展的 KMP
上面所说的 KMP 只能找到模式串在主串中出现的第一个位置,现在我们扩展一下,让它可以一次性找到在主串中所有适配的位置。
注意,既然我们说是“所有”位置,那就包括了重叠的部分,如下图所示:
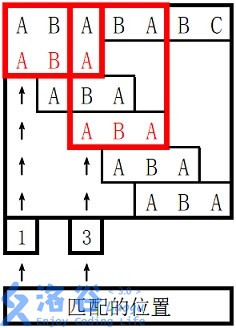
那么怎么做呢?我们仿照之前的思路,假设在 pattern 末尾也有一个虚拟的哨兵字符,这个字符不论碰到什么其他字符都不匹配。这样只要把匹配成功后当作一次新的失配,就可以和以前的代码逻辑联通了。
为此,我们把 next[] 数组多加一位就可以了,就像这样:
1 | void Construct(const string &pat, int next[]) |
然后在主算法中写成这样:
1 | void KMP(const string &src, const string &pat) |